Example: Using SIC Codes for Building a Predictive Model
This example is based on the example data set AnalyzingSICCodes.sta . This data file contains a categorical dependent variable with information on the profitability of a transaction with industrial clients in various industries, as recorded in the SIC Codes variable.
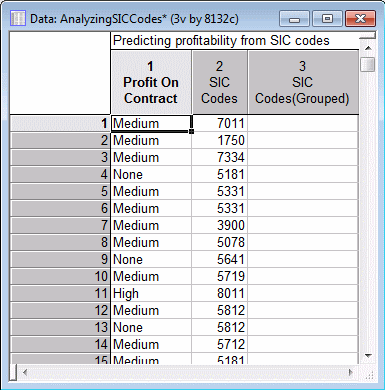
The purpose of the analysis is to recode the SIC codes into a smaller number of (aggregated) categories so that they can be included in subsequent model building.
Specifying the Analysis
Ribbon bar. Select the Home tab. In the File group, click the Open arrow and from the menu, select Open Examples. The Open a STATISTICA Data File dialog box is displayed. AnalyzingSICCodes.sta is located in the Datasets folder. After opening the data file, select the Data Mining tab. In the Clustering/Grouping group, click Optimal Binning to display the Optimal Binning Startup Panel.
Classic menus. From the File menu, select Open Examples to display the Open a STATISTICA Data File dialog box; AnalyzingSICCodes.sta is located in the Datasets folder. After opening the data file, from the Data Mining menu, select Optimal Binning for Predictive Data Mining to display the Optimal Binning Startup Panel.
Because the Profit on Contract variable that we will select is categorical, select the Categorical dependent (Classification) option button in the Analysis type group box on the Quick tab.
Click the Variables button, and select Profit On Contract as the dependent variable, SIC Codes as the categorical predictor variable, and (previously added to the file) SIC Codes(Grouped) as the output variable. Then, click the OK button in the variable selection dialog box.
We are now ready to begin the analysis and recode the output variable, so click the Summary button.
Reviewing Results
Two results spreadsheets will be displayed, and the final recoding will be applied to the output variable SIC Codes(Grouped).
- Results spreadsheets
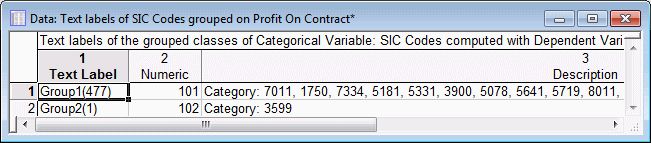
- The results spreadsheets contain summary information about which groups (codes) from the original input variable SIC Codes were combined into the newly recoded predictors.
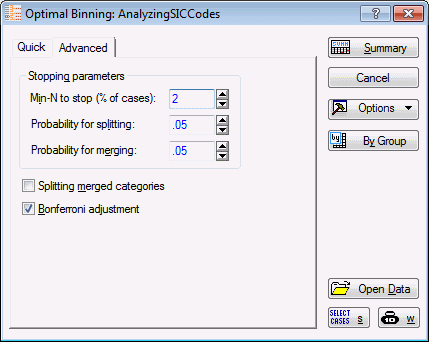
Using the default settings for the analyses, the results are not too useful. Apparently, only a single group was "split" off (identified) by the splitting (CHAID) algorithm. To ensure that in subsequent analyses we do not overlook useful (predictive) groupings of other SIC codes, let's go back to the Optimal Binning Startup Panel, and select the Advanced tab.
Set option Min-N to stop (% of cases) to 2. This will enable the algorithm to explore a wider variety of different splits, likely resulting in more groups (combinations of SIC codes) in the final results [for computational details, see also the documentation for General CHAID Models (GCHAID) and Interactive Trees (C&RT, CHAID)].
Now click the Summary button again, and review the results with these settings.
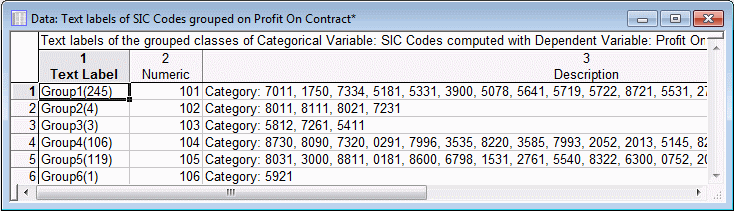
Now the algorithm identified 6 groups of SIC codes that appear to be related to the outcome variable of interest (Profit on Contract). The naming conventions for the newly recoded categories, consisting of sets of the classes from the original categorical predictor, are described in the documentation for the Optimal Binning Startup Panel. In short, each label Groupk(l) denotes each newly created category k, and the number l of classes or categories from the original categorical predictor that it contains.
The second results spreadsheet contains a row for each original code or class, and the category to which it was recoded.
Hence, these two summary spreadsheets contain the complete information on all recoding that was performed.
- Output variable
- In addition, the output variable selected for this analysis will automatically be recoded to contain the aggregated classes. Again, the naming conventions used in this variable are described in the documentation for the
Optimal Binning Startup Panel.
You can also display the Text Labels Editor for the output variable SIC Codes(Grouped) to review the results nature of the recoding that was applied (see also Using the Text Labels Editor and Notes on Text Labels and Text Values).