Technical Notes: The EM Algorithm
The EM algorithm is a general method of finding the maximum likelihood estimate of the parameters of underlying distributions from a given data set. We assume all variables are independent of each other and all data are from k joint distributions. The fundamental algorithm iterates between two steps.
- M-algorithm (Maximization step)
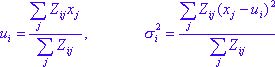
- E-algorithm (Expectation step)

where ui is the mean of distribution i. ![]() is the variance of distribution i.
is the variance of distribution i. ![]() is the estimated weight (probability) of observation j belonging to cluster i. ci represents the cluster i. p(xj) represents the probability.
is the estimated weight (probability) of observation j belonging to cluster i. ci represents the cluster i. p(xj) represents the probability.
If the increase value of likelihood is less than the value you specified, stop the iteration and get the final clustering. Also, if the number of the iterations is equal to the maximum number of the iterations, stop the iteration and get the final clustering.
For more information, see also the Introductory Overview.