SANN Overviews - Network Training
Training of Neural Networks
Once a neural network architecture is selected, i.e., neural network type, activation functions, etc., the remaining adjustable parameters of the model are the weights connecting the inputs to the hidden neurons and the hidden neurons to the output neurons. The process of adjusting these parameters so the network can approximate the underlying functional relationship between the inputs x and the targets t is known as training. It is in this process that the neural network learns to model the data by examples. Although there are various methods to train neural networks, implementing most of them involve numeric algorithms that can complete the task in a finite number of iterations. The need for these iterative algorithms is mainly due to the highly nonlinear nature of neural network models for which a closed form solution is not available most of time. An iterative training algorithm gradually adjusts the weights of the neural network so that for any given input data x the neural network can produce an output that is as close as possible to t.
Weights Initialization
Because training neural networks requires an iterative algorithm in which the weights are adjusted, one must first initialize the weights to reasonable starting values. This may sometimes affect not only the quality of the solution but also the time needed to prepare the network (training). It is important that you initialize the weights using small weight values so that, at the start of training, the network operates in a linear mode, and let it then increase the value of its weights to fit the data accurately enough.
STATISTICA Automated Neural Networks provides you with two random methods for initializing the weights using the normal and uniform distributions. The normal method initializes the weights using normally distributed values, within a range whose mean is zero and standard deviation equal to one. Alternatively, the uniform method assigns weight values in the range 0 and 1.
Neural Network Training - Learning by Examples
A neural network on its own cannot be used for making predictions unless it is trained on examples known as training data. The training data usually consists of input-target pairs that are presented one by one to the network during training to learn from them. You can view the input instances as "questions" and the target values as "answers." Thus, each time a neural network is presented with an input-target pair, it is effectively told what the answer is, given a question. Nonetheless, at each instance of this presentation, the neural network is required to make a guess using the current state (i.e., value) of the weights, and its performance is then assessed using a criterion known as the error function. If the performance is not adequate, the network weights are adjusted to produce the right (or a more correct) answer as compared to the previous attempt.
In general, this learning process is noisy to some extent (i.e., the network answers may sometimes be more accurate in the previous cycle of training as compared to the current one) but on the average the errors reduce in size as the network learning improves. The adjustment of the weights is usually carried out using a training algorithm, which like a teacher, teaches the neural network how to adopt its weights in order to make better predictions for each and every set of input-target pair example in the data set.
The above steps are known as training. Algorithmically it is carried out using the following sequence of steps:
- Present the network with an input-target pair.
- Compute the predictions of the network for the targets.
- Use the error function to calculate the difference between the predictions (output) of the network and the target values. Continue with steps 1 and 2 until all input-target pairs are presented to the network.
- Use the training algorithm to adjust the weights of the networks so that it gives better predictions for each and every input-target. Note that steps 1-5 form one training cycle or iteration. The number of cycles needed to train a neural network model is not known as a prior but can be determined as part of the training process.
- Repeat steps 1 to 5 again for a number of training cycles or iterations until the network starts producing sufficiently accurate outputs (i.e., outputs that are close enough to the targets given their input values). A typical neural network training process consists 100s of cycles.
The Error Function
As discussed previously, the error function is used to evaluate the performance of a neural network during training. It is like an examiner who assesses the performance of a student. The error function measures how close the network predictions are to the targets and, hence, how much weight adjustment should be applied by the training algorithm in each iteration. Thus, the error function is the eyes and ears of the training algorithm as to how well a network performs given its current state of training (and, hence, how much adjustment should be made to the value of its weights).
All error functions used for training neural networks must provide some sort of distance measure between the targets and predictions at the location of the inputs. One common approach is to use the sum-squares error function. In this case, the network learns a discriminant function. The sum-of-squares error is simply given by the sum of the squared differences between the target and prediction outputs defined over the entire training set. For convenience, this is typically scaled by 1/2N, and is given by:
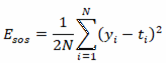
N is the number of training cases and yi is the prediction (network outputs) of the target value ti and target values of the i th datacase. It is clear that the bigger the difference between prediction of the network and the targets, the higher the error value, which means more weight adjustment is needed by the training algorithm.
The sum-of-squares error function is primarily used for regression analysis but it can also be used in classification tasks. Nonetheless, a true neural network classifier must have an error function other than sum-of-squares, namely cross entropy error function.
It is with the use of this error function together with a softmax output activation function that we can interpret the outputs of a neural network as class membership probabilities.
The cross entropy error function is given by:
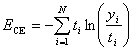
which assumes that the target variables are driven from a multinomial distribution. This is in contrast to the sum-of-squares error, which models the distribution of the targets as a normal probability density function.
NOTE: The training error for regression is calculated from the sum of squares error defined over the training set. However, the calculation is performed using the pre-processed targets (scaled from 0 to 1). Similarly, the test and validations error measures are defined as the sum of squares of the individual errors defined over the test and validation samples, respectively. Note that SANN also calculates the correlation coefficients for the train, test, and validation samples. These quantities are calculated for the original (unscaled) targets. On the other hand, for classification tasks SANN uses the so called cross-entropy error (see above) to train the neural networks but the selection criteria for evaluating the best network is actually based on the classification rate, which can be easily interpreted as compared to the entropy based error function.
The Training Algorithm
Neural networks are highly nonlinear tools that are usually trained using iterative techniques. The most recommended techniques for training neural networks are the BFGS (Broyden-Fletcher-Goldfarb-Shanno) and Scaled Conjugate Gradient algorithms (see Bishop 1995). These methods perform significantly better than the more traditional algorithms such as Gradient Descent but they are, generally speaking, more memory intensive and computationally demanding. Nonetheless, these techniques may require a smaller number of iterations to train a neural network given their fast convergence rate and more intelligent search criterion.
Training Multilayer Perceptron Neural Networks
STATISTICA Automated Neural Networks provides several options for training MLP neural networks. These include BFGS (Broyden-Fletcher-Goldfarb-Shanno), Scaled Conjugate, and Gradient Descent.
Training Radial Basis Function Neural Networks
The methods used to train radial basis function networks is fundamentally different from those employed for MLPs. This mainly is due to the nature of the RBF networks with their hidden neurons (basis functions) forming a Gaussian mixture model that estimates the probability density of the input data (see Bishop 95). For RBF with linear activation functions, the training process involves two stages. In the first stage, we fix the location and radial spread of the basis functions using the input data (no targets are considered at this stage). In the second stage, we fix the weights connecting the radial functions to the output neurons. For identity output activation functions, this second stage of training involves a simple matrix inversion. Thus, it is exact and does not require an iterative process.
The linear training, however, holds only when the error function is sum-of-squares and the output activation functions are the identity. If these requires are not met, i.e., in the case of cross-entropy error function and output activation functions other than the identity, we have to resort to an iterative algorithm, e.g., BFGS (Broyden-Fletcher-Goldfarb-Shanno), to fix the hidden-output layer weights in order to complete the training of the RBF neural network.