Example - Sequence Association Rules Applied to Microsoft Web Logs
Data File Description
The example file MSWebData.sta is based on data set records of visits to various areas of the Microsoft Web site WWW.microsoft.com, over a certain period of time. The anonymous visitors were selected at random. The areas of the Web site included those visited over a one-week period. Thus, the data set is suitable for sequence analysis.
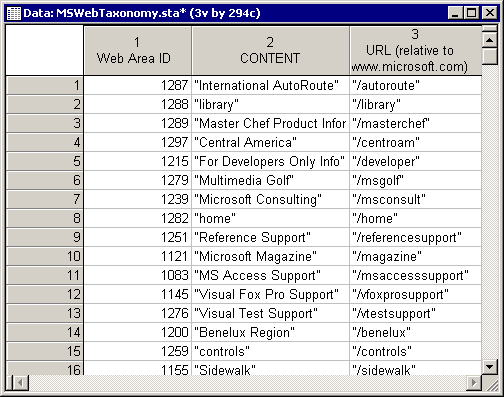
In the original data file, the users were identified by anonymous ID numbers and the 294 areas of the Microsoft Web site were identified by both titles and relative addresses to WWW.microsoft.com, e.g., the URL to the "International AutoRoute" would be WWW.microsoft.com/autoroute (see MSWebTaxonomy.sta described below). Each case in the data set represents an anonymous and randomly selected visit by a specific user to an area of the Web site.
Due to the sparse nature of the original data set, we will be using a pre-processed version of the data file: MSWebData.sta (located in the /Examples/Datasets directory of STATISTICA). In this stacked version, the data set consists of three variables (columns). The first variable, Visitor ID, is the visitor identification number. Variable two, Web Area ID, contains the area IDs, and the third variable, Time, indicates the sequence in which users visited the Web sites. We can read from the first three cases, for example, that user 10001 visited area 1000 ("regwiz") followed by a subsequent visit to 1001 ("Support Desktop") and finally 1002 ("End User Produced View").

A complete translation of the area IDs to their descriptive names/titles and relative addresses to WWW.microsoft.com is given in the taxonomy data file MSWebTaxonomy.sta (which also can be found in the /Examples/Datasets directory of STATISTICA). In this file, the Web Area ID contains the area identification numbers. The second and third variables, CONTENT and URL, contain the titles and addresses relative to WWW.microsoft.com. Both data files, MSWebData.sta and MSWebTaxonomy.sta are used in this example.
Purpose of the Analysis
In this step-by-step example, we aim to extract sequence rules from the data set MSWebData.sta for detecting patterns in surfing the Microsoft Web site WWW.microsoft.com. We want to extract rules that can predict sequential user visits to various areas of the Web site.
Specifying the Analysis
Open the data file MSWebData.sta and start Link Analysis. Following are instructions to do this from the ribbon bar and from the classic menus.
Ribbon bar. Select the Home tab. In the File group, click the Open arrow and select Open Examples to display the Open a STATISTICA Data File dialog. Double-click the Datasets folder, and then open the data set. Next, on the Data Mining tab, in the Rule Extraction group, click Link Analysis to display the Link analysis Startup Panel.
Classic menus. Open the data file by selecting Open Examples from the File menu to display the Open a STATISTICA Data File dialog. The data file is located in the Datasets folder. Then, from the Data Mining menu, select Sequence, Association and Link Analysis to display the Link analysis Startup Panel.
On the Quick tab, click the Variables button. In the variable selection dialog, select Visitor ID as the Sequence ID variable, Time as the Time variable, and Web Area ID as the Multiple response variable. Click the OK button.
There is no need to select the actual codes since the analysis will automatically pick up all distinct values found in the selected variables.
Next, select the Advanced tab to specify the parameters that will guide the sequence algorithm for identifying the existing rules.
For this particular example, change the Minimum support to 0.03 and leave all other options at the defaults. This will ensure that only rules achieving this level of support will be included in the results.
NOTE: In general, you may always want to start with the default settings for these parameters. If no sequence rules satisfying these conditions (i.e., with the required minimum support and minimum confidence) can be found in the data, STATISTICA SAL will issue a warning to that effect. You can then gradually relax these conditions, i.e., require lower minimum support and minimum confidence until a reasonable number of association rules can be found.
The parameter Maximum number of elements in an itemset is used to control the complexity of the rules derived from the data. Remember that, in general, rules have the form If Body then Head; so a sequence rule involving 10 items on each side of this sequence rule would be quite complex and may also have a small support value.
Select the Sequence tab to determine the maximum sequence size. We can do so by editing the value displayed in the Maximum number of itemsets in a sequence box. For this particular analysis, set this value to 35 (i.e., a sequence will contain a maximum of 35 items).
- Selecting taxonomies
- A particularly useful functionality for extracting rules is provided on the
Taxonomy tab, where we can convert the numeric item IDs (in this case Web Area IDs) to real and descriptive names. To do so, we need the taxonomy data file MSWebTaxonomy.sta (described above) located in the /Examples/Datasets directory of STATISTICA.
To load this file, select the Use Taxonomies for hierarchical association analysis check box on the Taxonomy tab. Next, click the Data file for taxonomies button to display a standard Open data file dialog where we can load MSWebTaxonomy.sta. Click the Assign taxonomy variables button to display the Assign item names and synonyms to variables dialog.
Select Item names and Web Area ID in the Items names and synonyms and Variables lists, and click the Assign button. This will set the Web Area IDs as Item names. Then, set CONTENT as the Synonym list. Click the OK button to accept these assignments and close the dialog.
On the Taxonomy tab, select the Remove original item labels when taxonomies are applied check box. This will exclude the original IDs from the results spreadsheets and graphs (which will be generated from the Results dialog).
- Saving models into database files
- STATISTICA SAL uses state-of-the-art database technology that makes rule extraction fast and memory efficient. All extracted rules and, hence, the model itself, are stored in a database (.dbs) file. The default name and location of this file is C:\Documents and Settings\USER\My Documents\Default.dbs. You can change this information in a way that suits your analysis best, e.g., C:\MSWebData.dbs. You will need this file later on for deploying/updating the sequence model (see below).
To initiate rule extraction, click the OK button. If a database file with the specified name and location already exists, a user information message will be displayed. If you click the Yes button, the analysis will proceed and the existing file will be deleted (contents will be lost). However, if you want to keep the file, which may contain valuable rules extracted from previous analyses, click the No button. This will cancel the sequence algorithm and take you back to the Link analysis Startup Panel where you can specify a new name and location for saving the database file.
Reviewing Results
In the Link Analysis Results dialog, you can select any number of items from the Item name list, a functionality that can be used in conjunction with generating certain types of spreadsheets and graphs only for the selected items, e.g., rule and web graphs (see below). To select a continuous range of items in sequential order, click on the first item in the range, hold down the SHIFT key, and click on the last item in the range. To select a number of items that are not in sequential order, press the CTRL key and click on the items one by one. To extend an existing selection by adding a new item, or to remove an item from the current selection, hold down the CTRL key and click on the item.
For this particular example, select the following items from the Item name list: Microsoft.com Search, Free Downloads, Windows Family of OSs, Products, and Internet Explorer.
The first thing you may want to review is the sequence rules in spreadsheet format. Click the Sequence rules button on the Quick tab to display this spreadsheet.
Note: in this spreadsheet a total of 22 rules have been extracted. The first rule represents If Support "desktop" Then "Knowledge Base." The support and confidence values for this rule are 3.286 and 24.151, respectively. Note that you can always reduce the number of rules extracted from the data set by assigning higher values to Minimum support and Min. confidence on the Link analysis Startup Panel Advanced tab.Similarly, you can display the list of frequent items in spreadsheet format by clicking the Frequent itemsets button. As you will notice, "Free Downloads" is by far the most popular (achieves the maximum frequency 10836).
NOTE: The options described above for generating summary of association rules and frequent itemsets are also available on the Advanced tab.
Instead of generating spreadsheets of rules and frequencies for all items, you may want to produce such outputs only for a number of selected items. To do so, select the items of interest from the Item name list. Select the Advanced tab of the Results dialog and click the Frequent itemsets only with selected items and Rules only with selected items buttons. You can also generate spreadsheets of rules where the selected items appear either as Bodies or as Heads using Rules only with selected items as bodies and Rules only with selected items as heads, respectively.
- 2D and 3D graphs
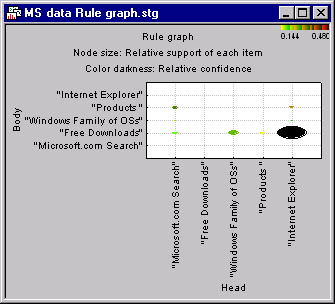
- Next, you may want to review the sequence rules your analysis has discovered in the form of graphs. First select the items for which you want to create rule or Web graphs. Note that at least two items must be selected in order to generate such outputs. Click the Rule graph button to produce the graphical summaries of the association rules. This summary is simply a 2D graphical representation of the information displayed in the Summary of sequential rules spreadsheet. The 2D association rule graph provides a summary of all the important information regarding the rules derived from the data. It is easy to see how all relevant statistics that describe the sequence rules are efficiently summarized in the sizes of circles and colors in this graph. Remember that sequence rules follow the general form If Body then Head. In this graph, the items identifying the Body of each rule are shown on the left side of the graph, the Head of each rule is shown on the right. The support and confidence values for the Body and Head portions of each association rule are indicated by the size and color of each circle.
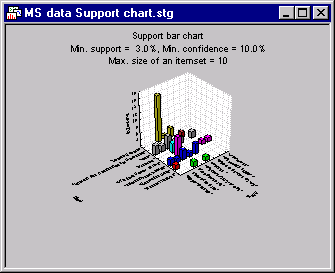
You can also create 3D histograms summarizing the values for support and confidence. These graphical outputs are available on the Advanced tab of the Results dialog. To create this graph, click the Support graph button.
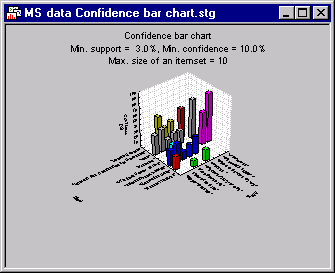
Click the Confidence graph button to display the confidence bar chart.
Finally, click the Disjoint sequences button on the Visualization tab to generate a spreadsheet containing the most complex rules discovered in your data during the current analysis. This spreadsheet is similar to the one you created earlier using the Frequent itemsets option, except that only the most complex rules are displayed here.
- Saving models for deployment
- When your analysis is complete, you may want to save the sequence model in PMML (Predictive Markup Model Language) format. PMML files can later be loaded and used in STATISTICA SAL using the deployment functionality provided on the
Project tab of the
Link analysis Startup Panel. To save the association model in a PMML file, click the PMML button located at the bottom of the
Results dialog. This will display a standard Save As dialog where you can send the output of the code generator to a single file with a name that you specify.
To finish the current analysis click the Cancel button. This will close the Results dialog and return you to the Link analysis Startup Panel where you may want to perform another analysis using the same or a different data set.
- Deployment
- Deployment enables you to apply existing sequence models, created from previous analyses, to new data in order to make further predictions (in STATISTICA SAL, models are saved either in database or PMML formats). This vital and important functionality is provided on the
Project tab of the Link analysis Startup Panel. Select the Use existing project option button to enable the rest of the controls displayed on this tab. At this point you have several choices:
Choice 1. You may want, for example, to use an existing database (.dbs) file to make predictions using the current data set. You can load a database file of your choice by clicking the Database file button. At this stage, you can either select the Update new transactions option button to update your sequence model with new data (this will make sense only if your current data set contains new transactions). Alternatively, you can select the Go to results dialog without adding transactions option button. This will take you to the Results dialog where you can simply make predictions using the active data set (no model updating will be performed).
Choice 2. Alternatively, you may want to deploy a sequence model using a previously saved PMML file. To do so, select the Recommendation via PMML option button. This will enable the PMML file button, used to load your PMML file (these files are saved with the extension .xml).
NOTE: The options on the Taxonomy tab will be unavailable when using an existing project.
Next, click the OK button. Choice one (described above) will take you to the Results dialog where you can generate outputs in the form of spreadsheets and graphs.
The second choice, will display a Results dialog specifically designed for making predictions using PMML files. For example, to make a simple query for the item "Products " as Body, enter the item name in the Enter antecedent itemsets(s) white box as follows
("Products ")
and then click the Query of rules button to produce a spreadsheet of rules involving "Products " as Body.
More complex queries are also possible such as
("Products "; "isapi") ("Free Downloads"; "Developer Network")
If no rules were found, which is likely for highly complex rules, STATISTICA SAL will issue a message to that effect.
Summary
This example illustrates the basic mechanism of applying sequence rule analysis for identifying relationships between variables, items, responses, etc. This method is particularly well suited for text and Web mining tasks of large data sets. When clear results can be derived, the results are always interpretable, understandable, and deployable because they consist of very simple If "Body" Then "Head" rules.