Edge Scoring Using Boomi AtomSphere®
Rationale
Boomi integration platform provides a gateway to data in the cloud. The Statistica platform is primarily an Enterprise-level on-premise solution, though cloud deployment is possible.
- Statistica users want to consume the data available in the cloud to explore it, build models, and use them to score new data.
- Boomi users want to score their data in the cloud, using models developed in Statistica.
Some of the basic integration patterns work out of the box. For instance, after you deploy a Boomi Atom on the on-prem Statistica Server, you can use the local DBMS system (or even flat file types) to stage data in and out for Statistica Server or Live Score. Boomi has integration points with Web Services that allow a Boomi integration process node to initiate a Statistica process, and vice versa.
Edge Scoring use case
Boomi can now consume analytic models developed in Statistica and deploy them as processing steps that can be executed near the data in the cloud. The use case described below is particularly relevant to IoT environments. It is called Edge Scoring because it performs analytic transformations and decisions at the edges of the IoT network, close to the physical data sources, such as sensors.
Since Statistica is able to generate a Java code representation of its analytic models. The resulting code can be obtained by Boomi, then be automatically compiled into executable integration nodes. You can apply these nodes to edge/cloud data inputs to produce actionable decisions. The Java code is self-contained and does not depend on Statistica components at run time.
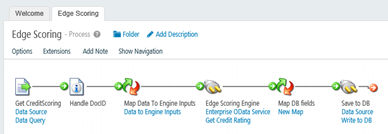
Getting Started
Drop in a new Statistica
Connector node/shape into the integration process canvas to display a
Connector Shape configuration:
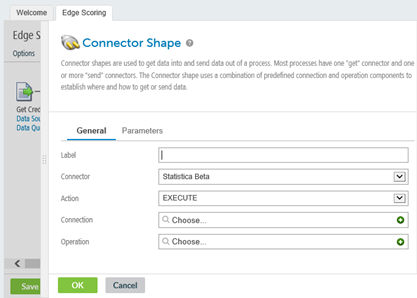
Name the connector instance, then define or select a previously defined Connection and Operation.
First Connection:
- In the New Statistica Beta
Connection dialog box, specify a valid Statistica Enterprise
OData service URL.
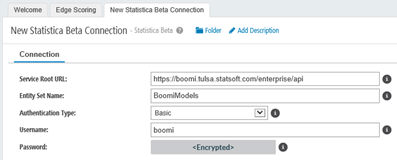
- Choose
Basic authentication and enter valid Statistica Enterprise user credentials.
Note: If you plan to use the HTTPS version of the Statistica endpoint (which we recommend, considering Basic authentication characteristics), make sure that the Boomi Atoms on which the integration process is to be deployed have the appropriate certificates imported. Otherwise, Boomi fails to connect to that endpoint.
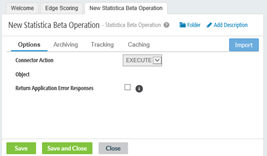
Operation Settings:
- After defining and saving the
Connection definition, proceed to
Operation settings. On the
Operation dialog box locate and click the
Import button:
- On the resulting Statistica Import Wizard dialog box, from the drop down list, choose the Atom instance to operate on.
- Choose the previously-defined
Connection, and specify the
Filter to filter the models available on the Statistica side.
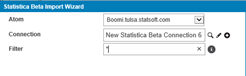
The filtering is currently performed by model name. These are some options you can use: - At this point Boomi connects to Statistica and query it for available models. The list displays in the drop down list on the next dialog box:

- Select the model of interest and click Next. Boomi now retrieves the Java representation of the selected model and the PMML file that describes model inputs/outputs in XML.
- Next, it creates
Request Profile and Response Profiles – formal definitions of those model inputs and outputs that allow you to wire up the processing node to the rest of the integration process:

- Select Finish on the Statistica Beta Import Wizard dialog box.
- Select Save and Close on the Operation Configuration dialog box. You have now completed the configuration of the Statistica Connector.
- Select
OK to save.
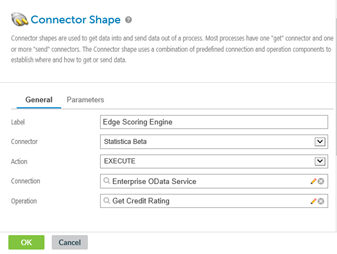
The connector can now be wired up as part of the integration process.
You can use the request and response profiles that you just created to configure input and output maps for the connector.

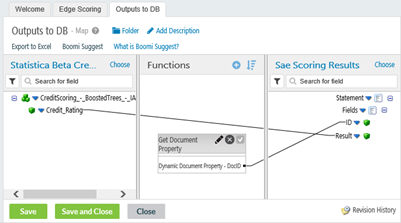
EXAMPLE: A Document ID is a case/record identifier of the entity being scored. It would not be part of the analytic transformation, but would be necessary to associate the resulting model decision to the input record being scored.
One more step might be necessary to correctly support such data pass:
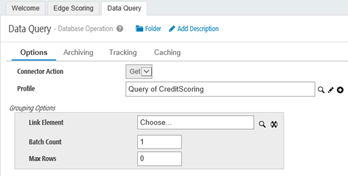
Adjust the settings of the Start connector/shape to make sure cases/records are returned as separate documents. Otherwise, all records might be passed into the process as a single document and document properties might not work as expected. For Database Start connector, set the Batch Count to 1 in the Grouping Option box.
Enterprise OData Service
The following section provides an overview of the REST API exposed by the Statistica Enterprise OData connector (a web service that can be installed as part of Statistica Enterprise Server installation and that serves Statistica models to Boomi). While you do not have to understand these lower-level details to use the Edge Scoring functionality, this knowledge might help with demos and diagnostics, in case things don’t work as expected.
After installation, the service is available in this format:
http://server/enterprise/api. The server is the name of the target host to which the web service was installed.
- It implements OData Version 4 – the latest standard for creating and consuming RESTful application interfaces (APIs). See http://www.odata.org for details. Service metadata can be retrieved from http://server/enterprise/api/$metadata.
- It supports Basic authentication. The users (and their credentials) are defined in the Enterprise user database.
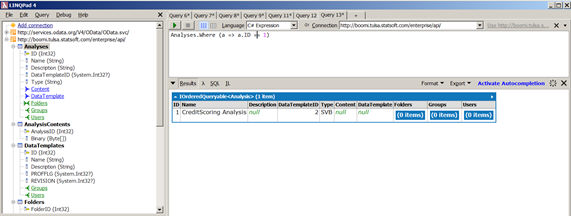
- This service exposes (at this moment a subset of) the Statistica Enterprise database – items like analyses, data templates, folders, users, and groups. Of interest to the Boomi Edge Scoring use case are:
| Folders | Analyses |
|
EXAMPLES: |
You can explore the
API using a range of clients that support
HTTP (REST) and optionally
OData. You can use browsers (directly or using helper plugins like
Chrome Postman) or command line tools like
CURL or an app like
LINQPad v4, for instance: