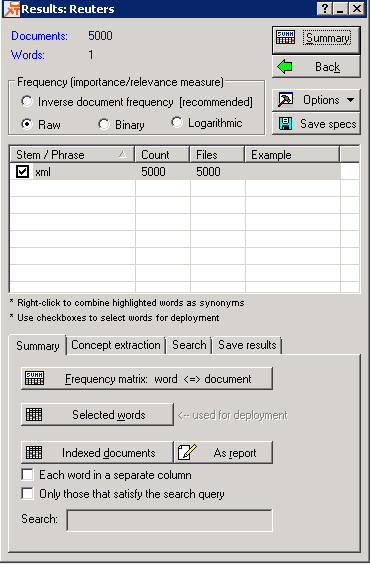
The
Results dialog contains numerous options for summarizing the frequency counts of different words and terms. You can also combine terms or phrases (to count them as a single term or phrase), or clear only some of the terms in the analyses.
Click the
Index button in the
Text Mining dialog box to display the
Results dialog box, which contains four tabs: Summary, Concept extraction, Search, and Save results.
The top area of the dialog box displays the number of documents in the term-document index (Documents), as well as the number of selected (and unselected, if applicable) terms stored in that index (Words).
When you request the Frequency matrix (on the Summary tab), or perform singular value decomposition (via the Concept extraction tab), the respective computations and summaries are computed and reported for the chosen transformation only (e.g., singular value decomposition can be performed for the raw Frequency counts, Inverse document frequency statistics, and so on).
| Option
|
Description
|
| Frequency (importance/relevance measure)
|
You can compute various statistical summaries for each word within each document. These are mostly simple transformations of the original word frequencies, in order to achieve more meaningful indices with values and distributions of words across the documents. These indices are suitable for subsequent analyses using other statistical or data mining techniques. Use the options in this group box to choose one of these common transformations (or to use raw word frequencies). When you request the Frequency matrix (on the Summary tab), or perform singular value decomposition (via the Concept extraction tab), the respective computations and summaries are computed and reported for the chosen transformation only (example, singular value decomposition can be performed for the raw Frequency counts and Inverse document frequency statistics).
|
| Inverse document frequency [recommended]
|
Select this option button to analyze and report inverse document frequencies.
One issue that you may want to consider more carefully, and reflect in the indices used in further analyses, are the relative document frequencies (df) of different words. For example, a term such as "guess" may occur frequently in all documents, while another term such as "software" may only occur in a few. The reason is that one might make "guesses" in various contexts, regardless of the specific topic, while "software" is a more semantically focused term that is only likely to occur in documents that deal with computer software. A common and very useful transformation that reflects both the specificity of words (document frequencies) as well as the overall frequency of their occurrences (word frequencies) is the inverse document frequency (for the i'th word and j'th document):
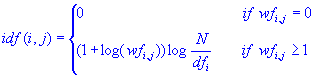
In this formula (see also formula 15.5 in Manning and Schütze, 2002), N is the total number of documents, and dfi is the document frequency for the i'th word (the number of documents that include this word). Hence, it can be seen that this formula includes both the dampening of the simple word frequencies via the log function, and also includes a weighting factor that evaluates to 0 if the word occurs in all documents (log(N/N=1)=0), and to the maximum value when a word only occurs in a single document (log(N/1)=log(N)). It can easily be seen how this transformation will create indices that both reflect the relative frequencies-of-occurrences of words, as well as their semantic specificities over the documents included in the analysis.
|
| Raw
|
This is the default selection that enables you to operate on raw word frequencies collected in the term-document index.
|
| Binary
|
Select this option button to analyze and report binary indicators instead of word frequencies. Specifically, this option will simply enumerate whether a term is used in a document; i.e.:
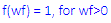
Where wf stands for word frequency within each document. The resulting documents-by-words matrix will contain only 1s and 0s, to indicate the presence or absence of the respective word. As the other transformations of simple word frequencies, this transformation will dampen the effect of the raw frequency counts on subsequent computations and analyses.
|
| Logarithmic
|
Select this option button to analyze and report logs of the raw word frequencies. A common transformation of the raw word frequency counts (wf) is to compute:

This transformation will dampen the raw frequencies and how they will affect the results of subsequent computations.
|
List of selected words: This list displays the words that were extracted from the documents and their frequencies (the overall word frequencies as well as document frequencies, i.e., number of documents in which they were found). You can sort by each column in the list of extracted and selected words by clicking on the respective column header. For example, to sort by the word itself, click on the
Stem/Phrase column header. Click on the
Count
header to sort by the total word frequencies (click once to sort in ascending order, click again to sort in descending order).
| Option
|
Description
|
| Stem/Phrase
|
This column lists the terms as they were indexed (stored in the internal database), that is, after stemming. This column will also list phrases (user-defined word combinations that should be treated as a whole), if present.
The entries in the
Example column show the shortest original words that were reduced to the respective stem, unless such a word is the stem itself, in which case the entry is empty.
The list’s check box controls near each term enable you to select/deselect some of the words in the index. It is important to distinguish between selected and unselected words versus indexed and non-indexed words. Words or terms can be indexed in the (internal) database but not selected into the word list from which final results are computed (e.g., singular value decomposition). If the
Keep unselected words in database for browsing option on the
Advanced tab of the
Text Mining dialog box is selected, the list will display all words contained in the term-document index, even the ones that did not pass automatic selection conditions; in this case, you can perform word selection manually.
The
Count column displays the total word frequencies.
The
Files column displays the document frequencies of listed words.
|
| Summary
|
Click this button to generate the term-document matrix (the same results as the option
Frequency matrix: word <=> document on the
Summary tab). Specifically, the results spreadsheet will contain a row for each input document, and a column for each word. The entries in the cells of the results spreadsheet depend on the option selection in the
Frequency (importance/relevance measure) group box in this dialog box. The summary spreadsheet can quickly be turned into an input spreadsheet for subsequent analyses (use the options on the
Save results tab to write the respective word statistics to another file or database).
|
| Back
|
Click this button to close the
Results dialog box and return to the
Text Mining dialog box.
|
| Options
|
Click this button to display the
Options menu.
|
| Save specs
|
Click this button to display the
Save as file dialog box, where you can save analysis settings in order to reuse them later.
|